![[Transformer 쉽게 이해하기] - self-attention, multi-haed attention, cross-attention, causal attention 설명과 코드 설명](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F0cG3X%2FbtsDERrl5fS%2FxGrJq144ZxzmBvwzY3Jjik%2Fimg.png)
GPT4와 Llama같은 large language models (LLMs)는 모두 transformer 구조를 차용하고 그 안에서 self-attention을 사용합니다.
self-attention과 LLMs의 핵심 구성요소를 보도록 하겠습니다. 설명도 있지만, 코드도 함께 설명하도록 하겠습니다.
LLM을 만드는 과정
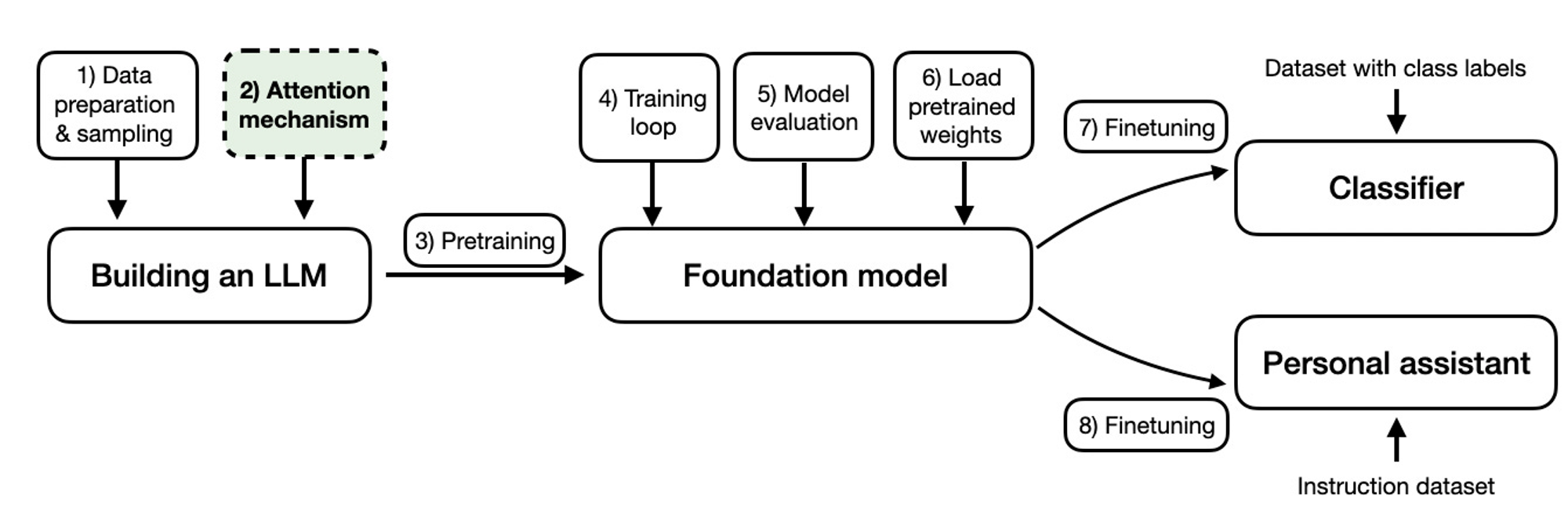
이 글을 읽기에 앞서, 기본적으로 LLM, attention mechanism에 대해 대충이라도 어느정도는 이해하시는 수준이면 좋을것 같습니다.
Self-Attention 소개
self-attention은 transformers(Attention is all you need)로부터 나온 개념인데, 요즘엔 어디에서나 쓰이고, 특히 NLP에서는 SoTA로써 여전히 사용되고 있는 모듈입니다. 그런만큼 self-attention에 대해 정확히 이해하는 것이 중요합니다.
Transformer의 self-attention 구조 그림
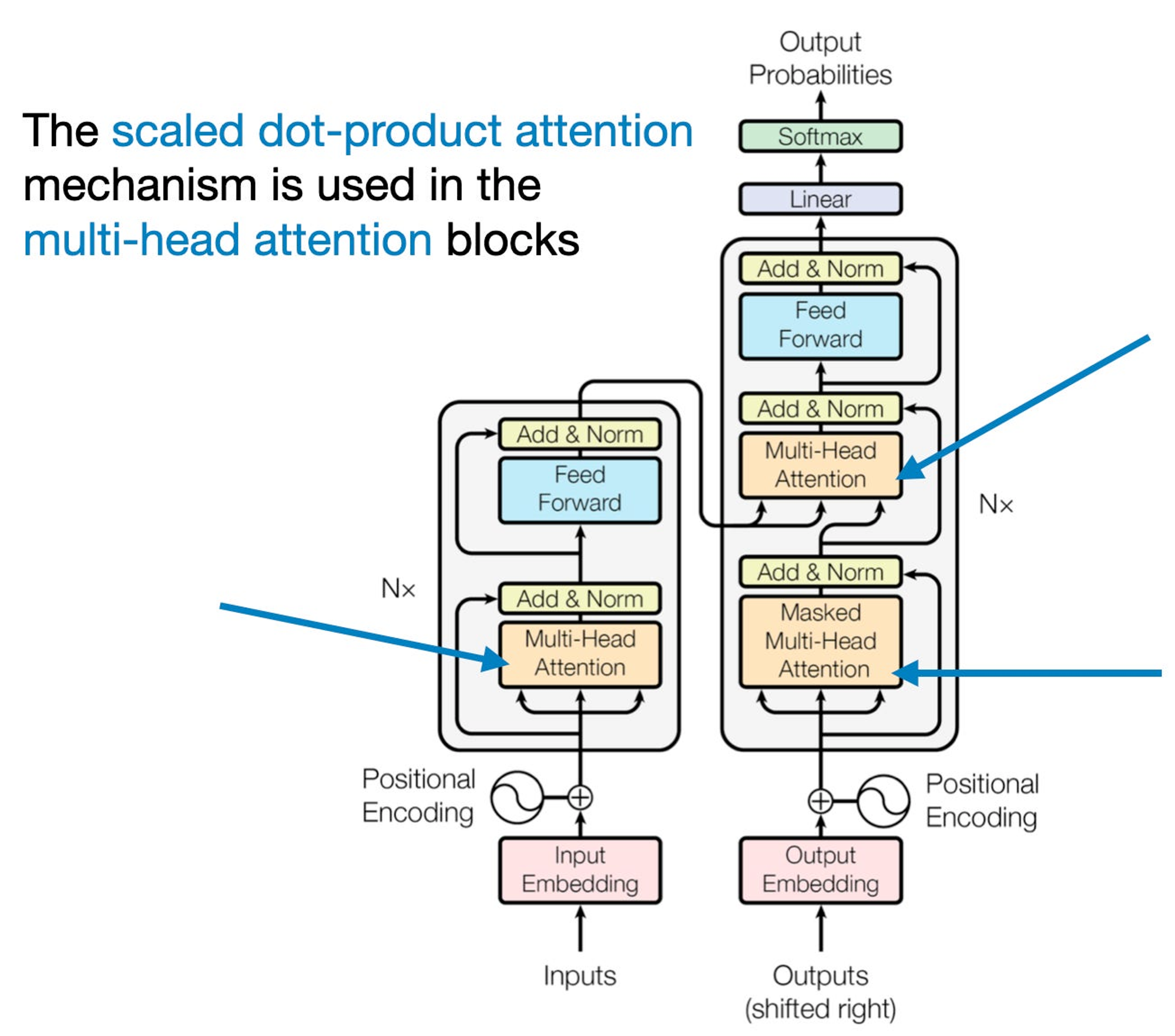
‘attention’이라는 컨셉은 사실 RNN로부터 유래했다고 할 수 있는데, 목적은 긴 sequence와 sentences를 다루기 위한 것이다. 언어를 다른 언어로 번역하는 경우를 예로 들면, 단어 하나씩만 따로 번역하는 것은 말이 안되는게, 언어마다 고유한 문법이 있고 문맥이 있기 때문이다. 따라서 그렇게 번역을 하면 부정확하고, 말이 안되는 문장이 나올것이다. (아래 빨간 글씨가 이 방식에 해당)
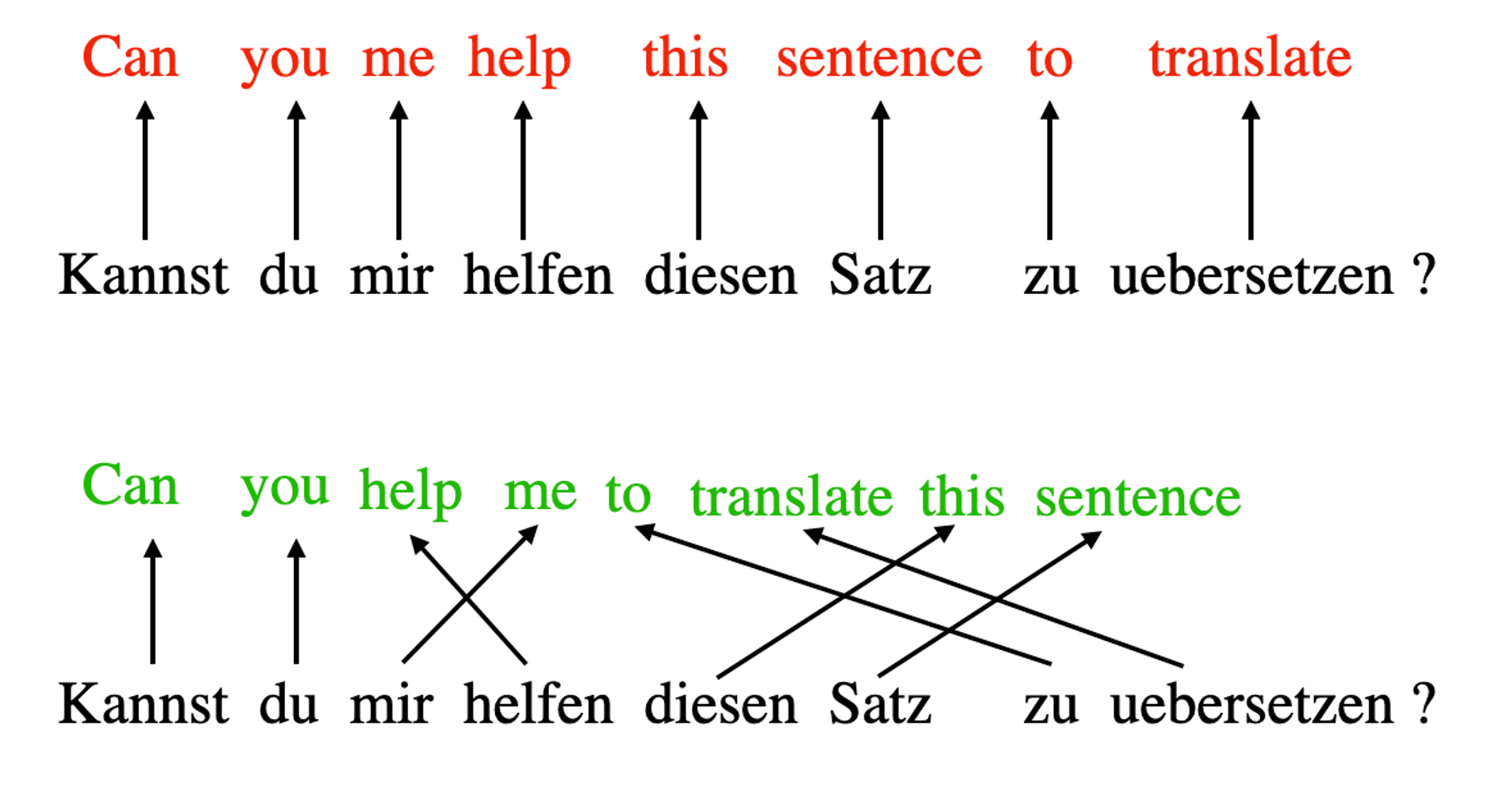
이 문제를 해결하기 위해, attention 매커니즘은 모든 sequence 각 time step마다 요소들이 서로 접근할 수 있는 방법을 소개한다. 핵심은 특정 context에서 무엇이 더 중요한지 선택하고 결정하는 것이다. 여기서 self-attention은 RNN을 필요성을 대체해버린다.
self-attention은 input embedding으로 하여금 보다 input의 문맥정보를 더 잘 포함하도록 해주는 메커니즘이라고 할 수 있습니다.
다시 말해서, self-attention은 모델이 input sequence로부터 각 요소(단어)의 중요성에 무게를 둬서 output에 다이나믹하게 영향을 줄 수 있도록 합니다.
self-attention엔 많은 종류가 있는데요, 각각 self-attention의 어떤 부분에 집중하느냐에 따라 효과가 달라집니다. 그러나, 대부분의 논문들은 오리지널인 scaled-dot product attention 매커니즘을 사용합니다. 그러므로 이 포스트에서는 오리지널 버전 attention만 다루도록 하겠습니다.
“Life is short, eat dessert first” 라는 문장이 있습니다. 이것을 self-attention에 입력한다고 생각해볼게요.
먼저 다른 NLP들도 그러하듯이 전처리를 해야합니다. sentence embedding을 먼저 만들어야 하죠
단순화하기 위해, dictionary dc를 이용해 input sentence를 각 사전에 맞게 tokenize해보겠습니다.
먼저, dictionary를 만들어 보면,
(주로 단어 dictionary는 3만~5만개 사이입니다.)
Input:
sentence = 'Life is short, eat dessert first'
dc = {s:i for i,s
in enumerate(sorted(sentence.replace(',', '').split()))}
print(dc)
Output:
{'Life': 0, 'dessert': 1, 'eat': 2, 'first': 3, 'is': 4, 'short': 5}
이제, dictionary에 맞게 sentence를 tokenize해줍니다.
Input:
import torch
sentence_int = torch.tensor(
[dc[s] for s in sentence.replace(',', '').split()]
)
print(sentence_int)
Output:
tensor([0, 4, 5, 2, 1, 3])
이제 이 input sentence에 대한 integer-vector representation을 real-vector embedding으로 encoding합니다. 3차원의 vector로 변환시켜볼게요.
메타의 Llama2의 경우에는 4,096의 vector size를 사용합니다. (여기서 3차원을 사용하는 이유는 단순화하기 위한겁니다. 4,096 size를 사용하면 페이지가 넘칠것입니다..)
sentence가 6 단어를 가지고 있으므로, 6by3-dimensional embedding이 나오게 됩니다.
Input:
vocab_size = 50000
torch.manual_seed(123)
embed = torch.nn.Embedding(vocab_size, 3)
embedded_sentence = embed(sentence_int).detach()
print(embedded_sentence)
print(embedded_sentence.shape)
Output:
tensor([[ 0.3374, -0.1778, -0.3035],
[ 0.1794, 1.8951, 0.4954],
[ 0.2692, -0.0770, -1.0205],
[-0.2196, -0.3792, 0.7671],
[-0.5880, 0.3486, 0.6603],
[-1.1925, 0.6984, -1.4097]])
torch.Size([6, 3])
Weight matrices 정의하기
이제, 주로 사용되는 self-attention 메커니즘의 scaled dot-product attention을 설명해보겠습니다.
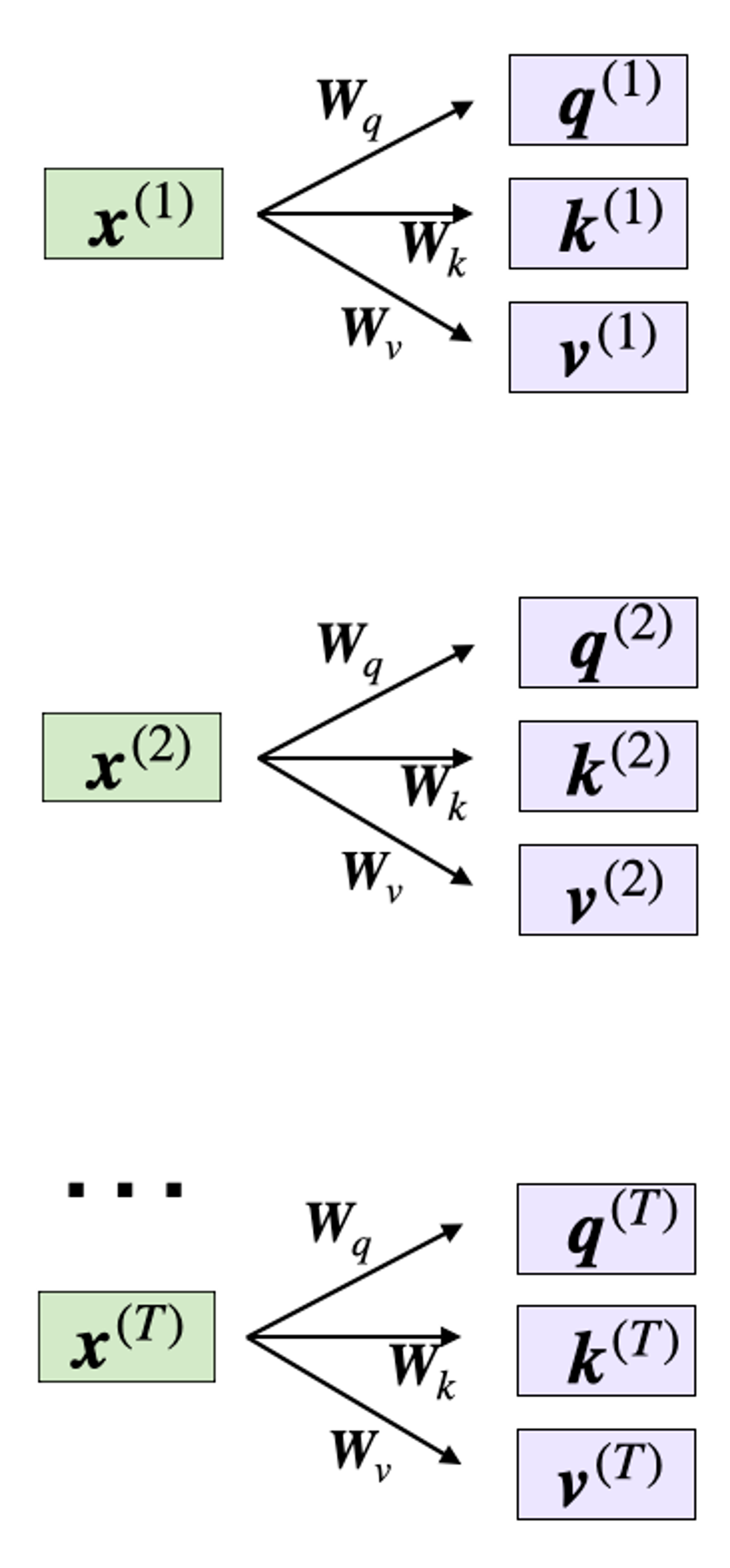
self-attention은 3개의 weight matrix를 사용하는데요, Wq, Wk, 그리고 Wv 입니다.
이것들은 학습중에 조정되는 weight들입니다. 이 matrices는 query, key, value 요소로 사용됩니다.
- Query sequence: q(i) = x(i)Wq for i in sequence 1 … T
- Key sequence: k(i) = x(i)Wk for i in sequence 1 … T
- Value sequence: v(i) = x(i)Wv for i in sequence 1 … T
index i는 input sequence의 token index position을 의미합니다. T는 length를 의미합니다.
d 를 dimension이라 했을때, dq = dk = 2, dv = 4 로 지정해주었습니다. 나중에 설명을 하겠지만 앞의 두개는 같게 설정해줘야 합니다.
In:
torch.manual_seed(123)
d = embedded_sentence.shape[1]
d_q, d_k, d_v = 2, 2, 4
W_query = torch.nn.Parameter(torch.rand(d, d_q))
W_key = torch.nn.Parameter(torch.rand(d, d_k))
W_value = torch.nn.Parameter(torch.rand(d, d_v))
이런식으로 각 단어당 query, key, value가 만들어집니다.
각각의 shape를 보면,
Input:
x_2 = embedded_sentence[1]
query_2 = x_2 @ W_query
key_2 = x_2 @ W_key
value_2 = x_2 @ W_value
print(query_2.shape)
print(key_2.shape)
print(value_2.shape)
Output:
torch.Size([2])
torch.Size([2])
torch.Size([4])
이런 방식으로 나머지 input에 대해 key, value를 계산할수 있습니다.
전체 sentence에 적용한다고 가정하면,
Input:
keys = embedded_sentence @ W_key
values = embedded_sentence @ W_value
print("keys.shape:", keys.shape)
print("values.shape:", values.shape)
Output:
keys.shape: torch.Size([6, 2])
values.shape: torch.Size([6, 4])
이제 모든 key, value들을 도출해내었고, unnormalized attention weights인 ω를 도출해낼수 있습니다.

그림처럼 ωi,j 는 query와 key의 dot으로 구합니다. ωi,j = q(i) k(j).
예를 들어, 5번째 input에 대한 unnormalized attention weight를 구할 수 있습니다. (index상은 4번째)
In:
omega_24 = query_2.dot(keys[4])
print(omega_24)
Out:
tensor(1.2903)
이 unnormalized attention weights ω는 실제 attention weight를 구하기 위해 나중에 필요합니다. 모든 input에 대해ω value를 구해보면,
In:
omega_2 = query_2 @ keys.T
print(omega_2)
Out:
tensor([-0.6004, 3.4707, -1.5023, 0.4991, 1.2903, -1.3374])
이런 오메가(unnormalized attention weight)들이 나오게 됩니다.
Computing the Attention Weights
그 다음은 unnormalized attention weight들을 normalize할 필요가 있습니다.
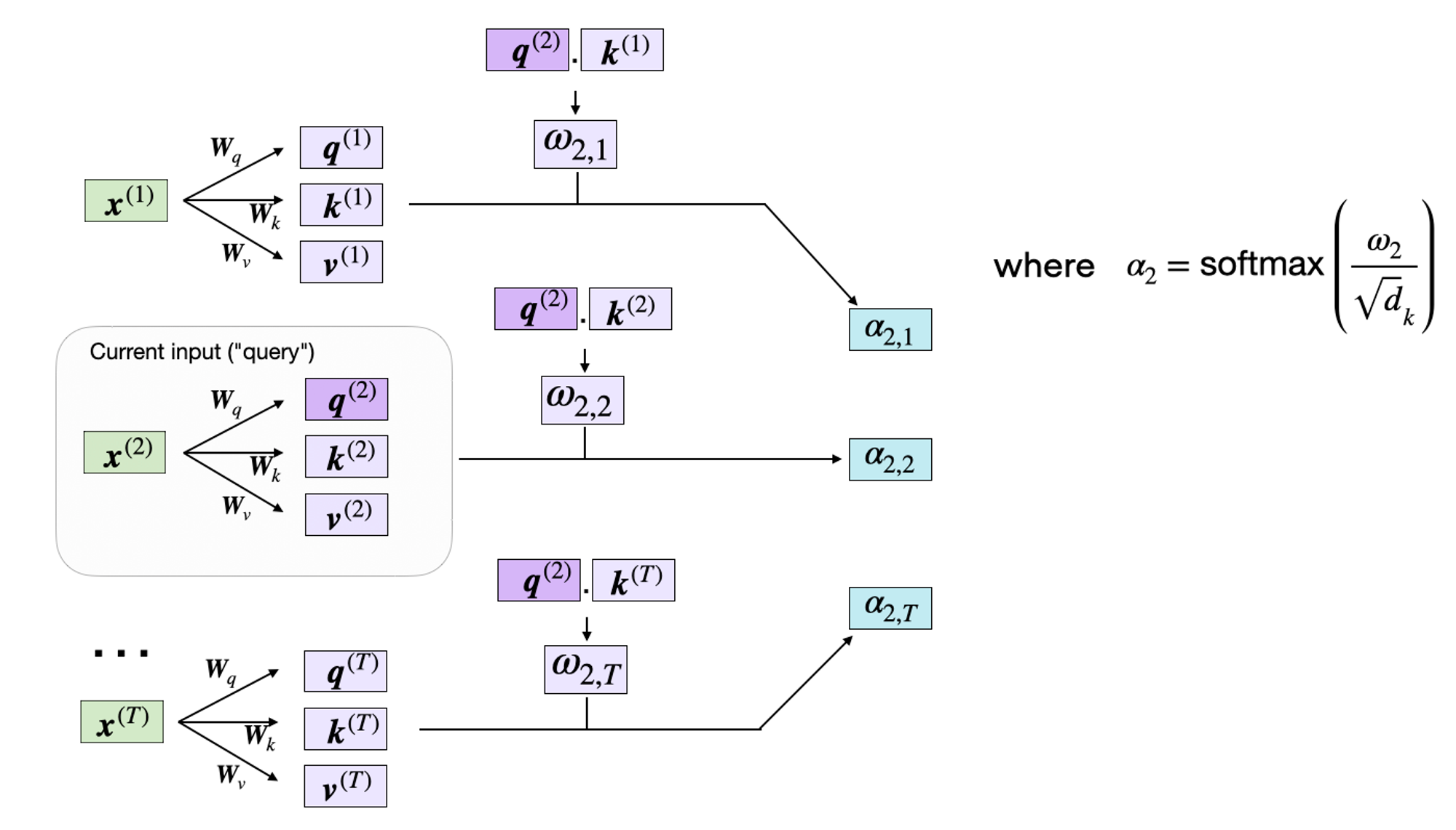
dk로 각 오메가들의 거리를 같게 해줍니다. 이것은 weights가 너무 크거나 작은 것을 방지해줍니다.
In:
import torch.nn.functional as F
attention_weights_2 = F.softmax(omega_2 / d_k**0.5, dim=0)
print(attention_weights_2)
Out:
tensor([0.0386, 0.6870, 0.0204, 0.0840, 0.1470, 0.0229])
마지막 step은 context vector z를 계산하는 겁니다. value에 알파를 곱해줍니다.
In:
context_vector_2 = attention_weights_2 @ values
print(context_vector_2.shape)
print(context_vector_2)
Out:
torch.Size([4])
tensor([0.5313, 1.3607, 0.7891, 1.3110])
output vector는 original input의 dim=3보다 큰 dim_v=4인데. 처음에 dq = dk = 2, dv = 4 로 지정해주었기 때문입니다. 다시한번 말하지만 dv 는 임의로 정할 수 있습니다.
Self-Attention
이제 self-attention 메커니즘의 전체를 구현하는 코드를 보겠습니다.
In:
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, d_in, d_out_kq, d_out_v):
super().__init__()
self.d_out_kq = d_out_kq
self.W_query = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_key = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_value = nn.Parameter(torch.rand(d_in, d_out_v))
def forward(self, x):
keys = x @ self.W_key
queries = x @ self.W_query
values = x @ self.W_value
attn_scores = queries @ keys.T # unnormalized attention weights
attn_weights = torch.softmax(
attn_scores / self.d_out_kq**0.5, dim=-1
)
context_vec = attn_weights @ values
return context_vec
In:
torch.manual_seed(123)
# reduce d_out_v from 4 to 1, because we have 4 heads
d_in, d_out_kq, d_out_v = 3, 2, 4
sa = SelfAttention(d_in, d_out_kq, d_out_v)
print(sa(embedded_sentence))
Out:
tensor([[-0.1564, 0.1028, -0.0763, -0.0764],
[ 0.5313, 1.3607, 0.7891, 1.3110],
[-0.3542, -0.1234, -0.2627, -0.3706],
[ 0.0071, 0.3345, 0.0969, 0.1998],
[ 0.1008, 0.4780, 0.2021, 0.3674],
[-0.5296, -0.2799, -0.4107, -0.6006]], grad_fn=<MmBackward0>)
Multi-Head Attention
다음으로 mult-head Attention과 self-attention의 관계를 설명해보겠습니다.
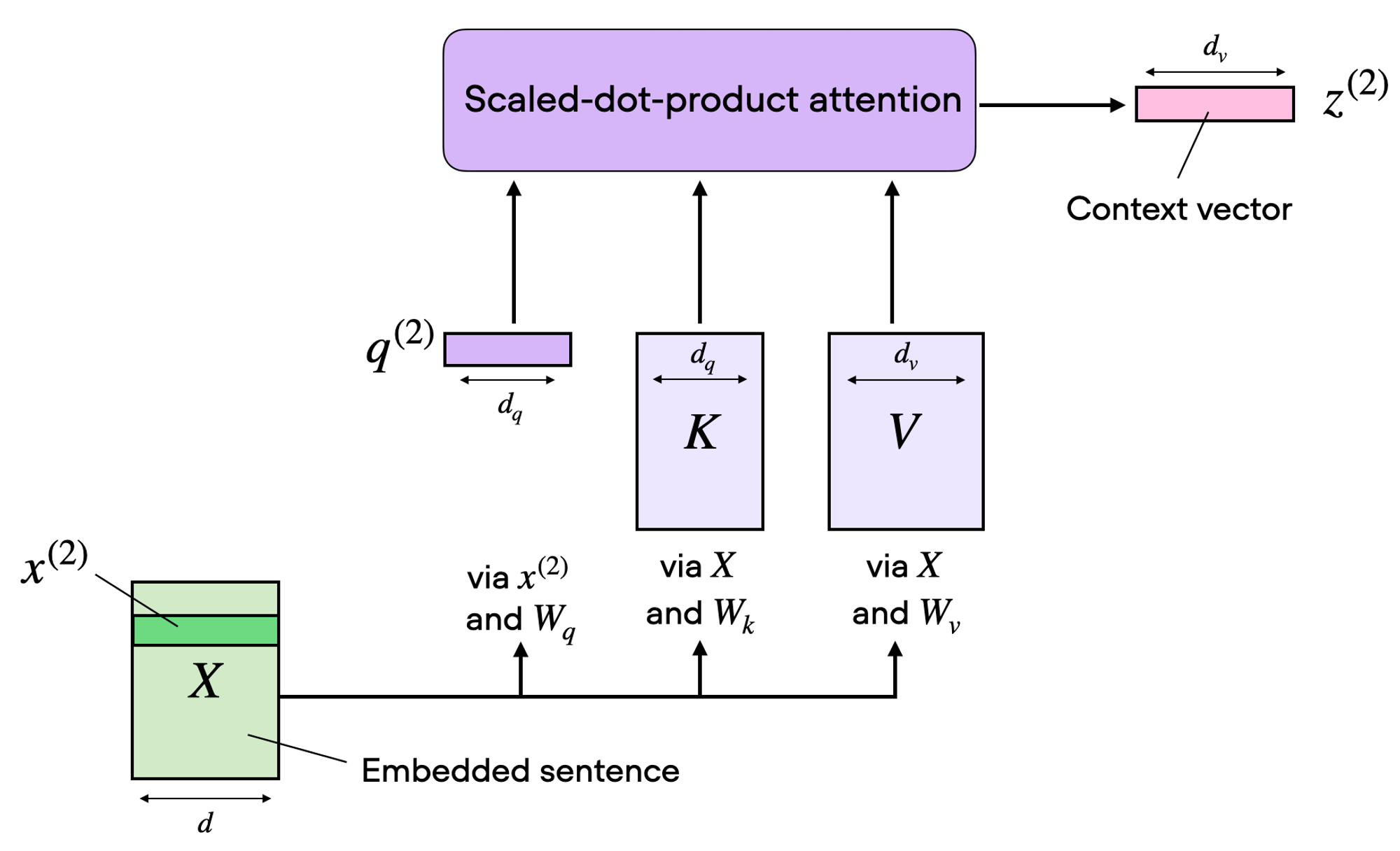
self attention을 위 그림과 같이 표현할 수 있습니다. scaled dot-product를 통해 input sequence를 query, key, value matrix로 만들었었죠.
이것을 여러개를 병렬적으로 하면 바로 multi-head attention이 되는데요, CNN(Convolutional Neural Network)의 kernal수와 같다고 생각하시면 될 것 같습니다.
class MultiHeadAttentionWrapper(nn.Module):
def __init__(self, d_in, d_out_kq, d_out_v, num_heads):
super().__init__()
self.heads = nn.ModuleList(
[SelfAttention(d_in, d_out_kq, d_out_v)
for _ in range(num_heads)]
)
def forward(self, x):
return torch.cat([head(x) for head in self.heads], dim=-1)
코드로는 위처럼 표현할 수 있습니다.
MultiHeadAttentionWrapper class 에서 자주쓰이는 변수를 정리하겠습니다.
- d_in: input feature vector의 Dimension (nn.Embedding의 끝 차원)
- d_out_kq: query, key 둘 다의 dimension
- d_out_v: value의 dimension
- num_heads: attention head 개수
각 attention head에서 다른 값이 도출 되는지 실험을 해보겠습니다.
In:
torch.manual_seed(123)
d_in, d_out_kq, d_out_v = 3, 2, 1
sa = SelfAttention(d_in, d_out_kq, d_out_v)
print(sa(embedded_sentence))
Out:
tensor([[-0.0185],
[ 0.4003],
[-0.1103],
[ 0.0668],
[ 0.1180],
[-0.1827]], grad_fn=<MmBackward0>)
Now, let's extend this to 4 attention heads:
In:
torch.manual_seed(123)
block_size = embedded_sentence.shape[1]
mha = MultiHeadAttentionWrapper(
d_in, d_out_kq, d_out_v, num_heads=4
)
context_vecs = mha(embedded_sentence)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
Out:
tensor([[-0.0185, 0.0170, 0.1999, -0.0860],
[ 0.4003, 1.7137, 1.3981, 1.0497],
[-0.1103, -0.1609, 0.0079, -0.2416],
[ 0.0668, 0.3534, 0.2322, 0.1008],
[ 0.1180, 0.6949, 0.3157, 0.2807],
[-0.1827, -0.2060, -0.2393, -0.3167]], grad_fn=<CatBackward0>)
context_vecs.shape: torch.Size([6, 4])
multiple attention heads 를 사용함으로써 얻을 수 있는 이점은 단순히 model capacity를 늘리는 장점 뿐만 아니라, 여러 set의 feature를 만듬으로써 다양한 관점으로 context관계를 도출해내는 앙상블 효과를 이뤄내는 것입니다. the 7B Llama 2 model은 32 attention heads를 사용합니다.
Cross-Attention
지금까지 배운 self-attention을 그림으로 요약하면 밑과 같습니다.
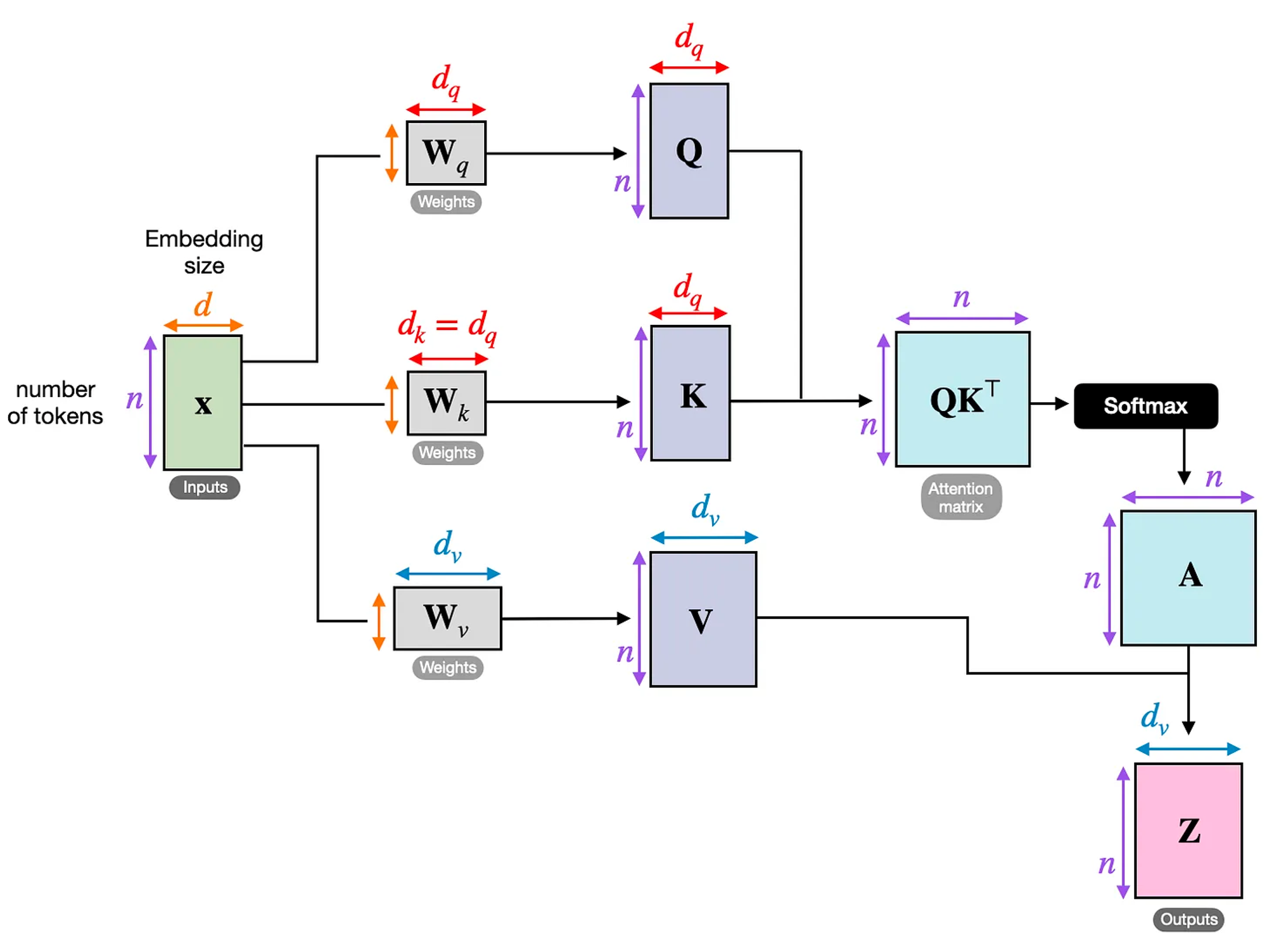
이제 Cross-attention을 들여다 보겠습니다.
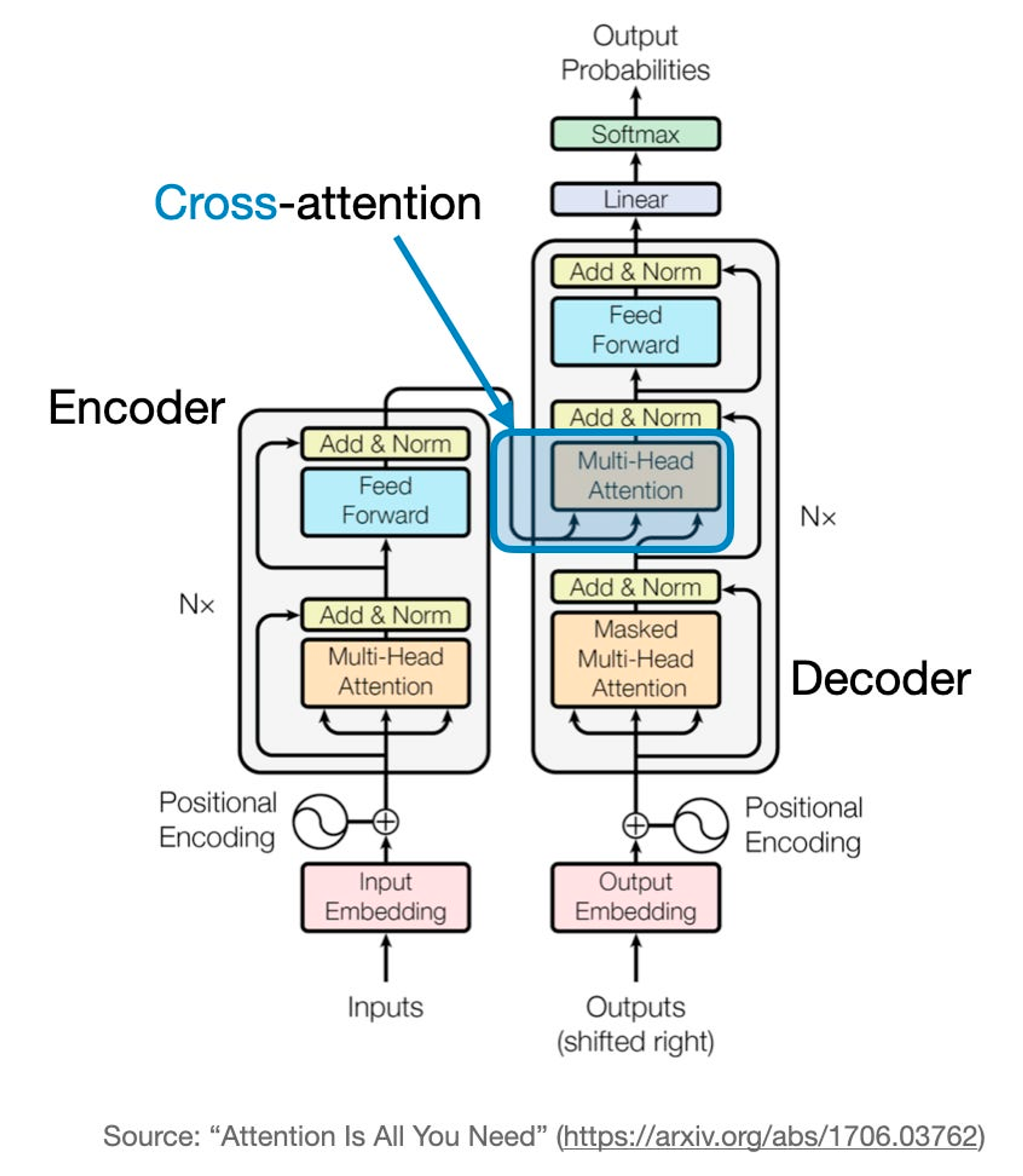
cross-attention은 무엇이고, self-attention과 무엇이 다를까요?
self-attention은 같은 input sequence에 대해 적용됩니다. 근데 cross-attention은 두 개의 다른 input sequence를 mix하고 조합합니다.
위 그림의 original transformer에선 왼쪽의 encoder 모듈로부터 얻어진 input sequence와 오른쪽 decoder part에 input sequence로 들어온 것을 의미합니다.
밑에는 위의 설명을 나타내는 cross attention을 나타낸 것입니다.
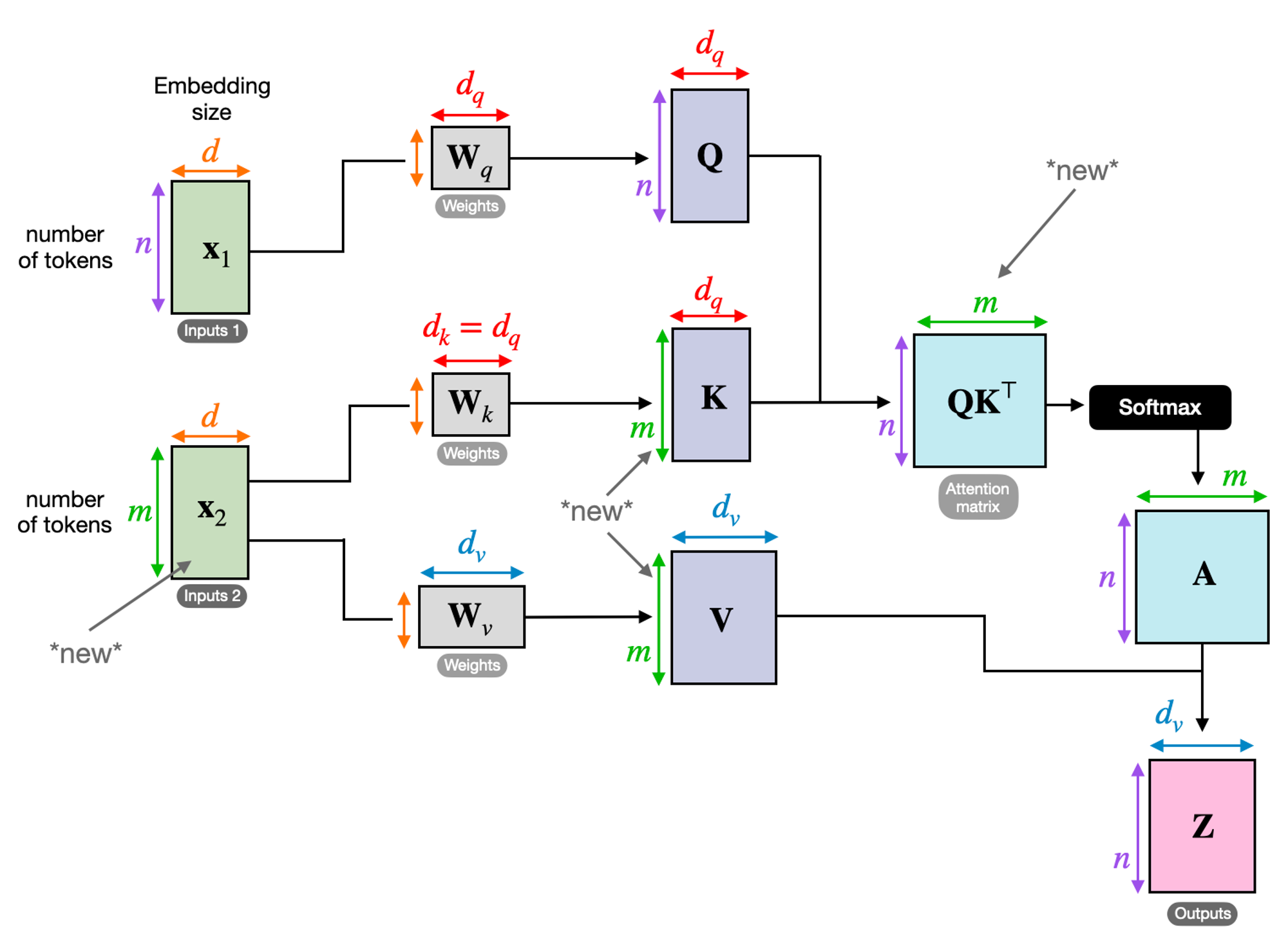
query가 보통 decoder로부터 오고, key, value는 encode로부터 옵니다.
코드로 보면,
In:
class CrossAttention(nn.Module):
def __init__(self, d_in, d_out_kq, d_out_v):
super().__init__()
self.d_out_kq = d_out_kq
self.W_query = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_key = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_value = nn.Parameter(torch.rand(d_in, d_out_v))
def forward(self, x_1, x_2): # x_2 is new
queries_1 = x_1 @ self.W_query
keys_2 = x_2 @ self.W_key # new
values_2 = x_2 @ self.W_value # new
attn_scores = queries_1 @ keys_2.T # new
attn_weights = torch.softmax(
attn_scores / self.d_out_kq**0.5, dim=-1)
context_vec = attn_weights @ values_2
return context_vec
CrossAttention class와 이전의 SelfAttention class 차이는 다음과 같습니다:
- forward 가 두개의 다른 inputs을 받습니다, (x_1 ,x_2). query는 x_1 으로부터 오고, key, value는 x_2 로부터 옵니다. 이것은 어텐션 메커니즘이 다른 두 개의 input들을 대해 계산하는 것을 의미합니다.
- SelfAttention 과 비슷하게, 각 context vector는 value들의 weight 합입니다. 그러나, CrossAttention의 이 value들은 두 번째 input으로부터 왔고(x_2), 그 weight들은 x_1, x_2의 상호작용으로 만들어진 것입니다.
torch.manual_seed(123)
d_in, d_out_kq, d_out_v = 3, 2, 4
crossattn = CrossAttention(d_in, d_out_kq, d_out_v)
first_input = embedded_sentence
second_input = torch.rand(8, d_in)
print("First input shape:", first_input.shape)
print("Second input shape:", second_input.shape)
Out:
First input shape: torch.Size([6, 3])
Second input shape: torch.Size([8, 3])
In:
context_vectors = crossattn(first_input, second_input)
print(context_vectors)
print("Output shape:", context_vectors.shape)
Out:
tensor([[0.4231, 0.8665, 0.6503, 1.0042],
[0.4874, 0.9718, 0.7359, 1.1353],
[0.4054, 0.8359, 0.6258, 0.9667],
[0.4357, 0.8886, 0.6678, 1.0311],
[0.4429, 0.9006, 0.6775, 1.0460],
[0.3860, 0.8021, 0.5985, 0.9250]], grad_fn=<MmBackward0>)
Output shape: torch.Size([6, 4])
Stable diffusion이라는 모델에서도 cross-attention 개념이 쓰입니다. 이것은 U-Net model에서 생성된 이미지 사이와 text prompts 사이에서 cross-attention을 사용합니다.
Causal Self-Attention
Causal self-attention에 대해 설명해보겠습니다.
GPT 같은 LLMs는 text를 생성해냅니다. 이 causal self-attention은 종종 “masked self-attention” 이라고 불리기도 하는데요. original transformer에선 “masked multi-head attention”이라고 불립니다.
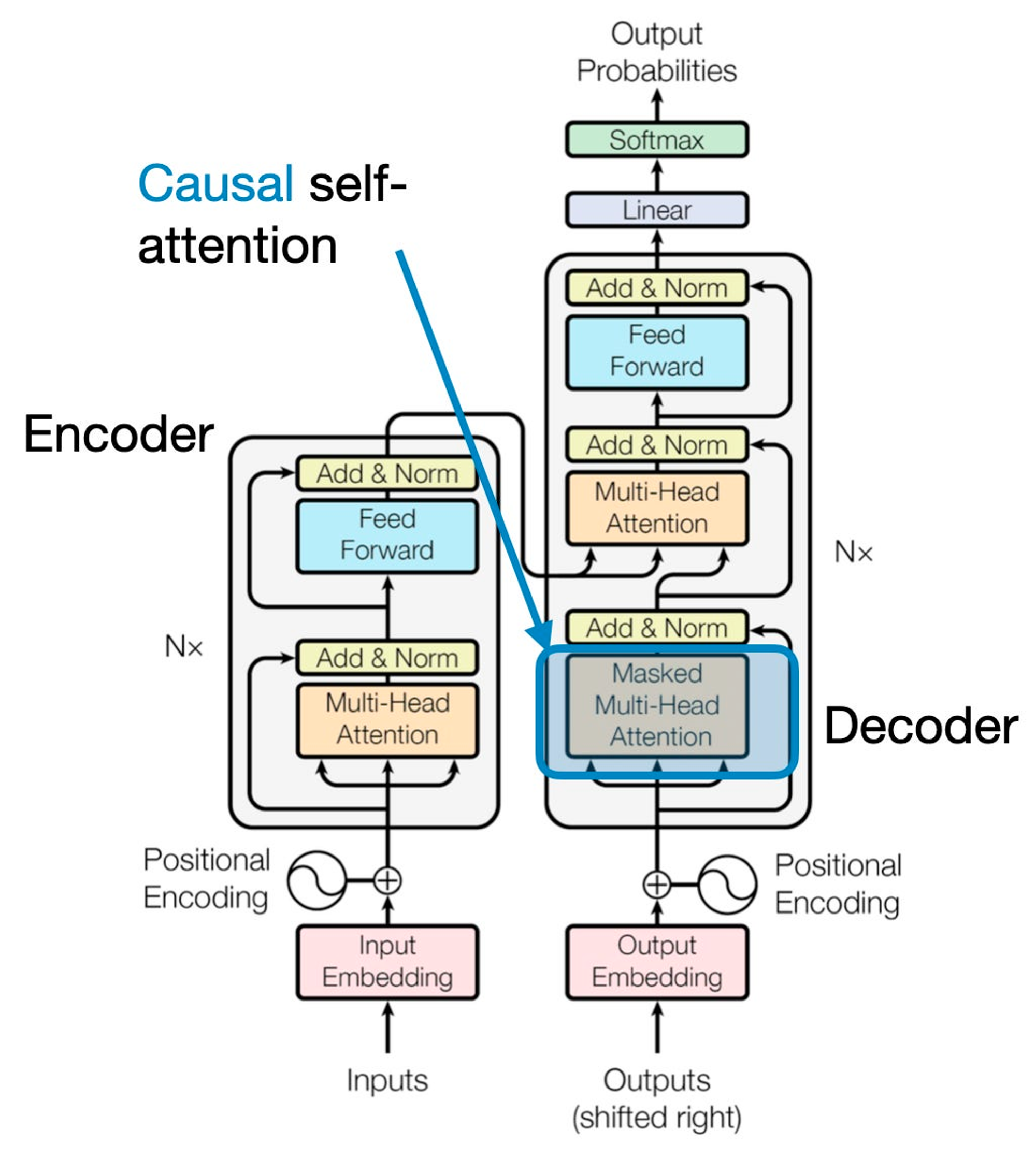
Causal self-attention은 sequence에서 특정 position에서의 output을 도출해냅니다. (물론 이전까지에 대해선 알고 미래에 나올 단어들에 대해서는 모르는 상태입니다.)
다시 말해서, 다음에 나올 단어를 이전에 도출해낸 단어들만 가지고서 ‘예측’하는 것입니다.
그래서 미래에 나올 token들을 mask 씌운채로 학습을 하는겁니다.
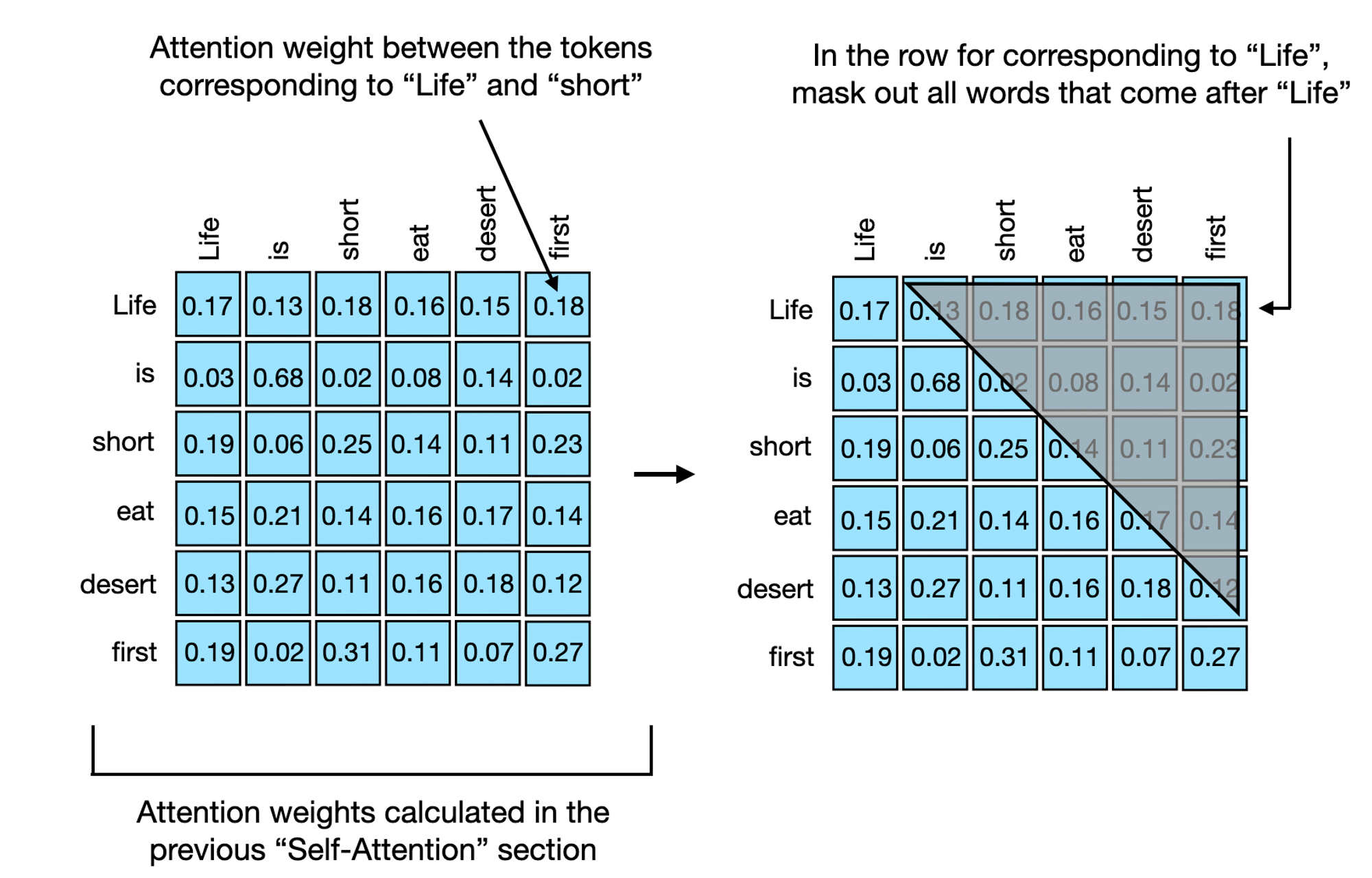
위 그림과 같이 표현할 수 있는데요, 코드로 다시 보겠습니다.
In:
torch.manual_seed(123)
d_in, d_out_kq, d_out_v = 3, 2, 4
W_query = nn.Parameter(torch.rand(d_in, d_out_kq))
W_key = nn.Parameter(torch.rand(d_in, d_out_kq))
W_value = nn.Parameter(torch.rand(d_in, d_out_v))
x = embedded_sentence
keys = x @ W_key
queries = x @ W_query
values = x @ W_value
# attn_scores are the "omegas",
# the unnormalized attention weights
attn_scores = queries @ keys.T
print(attn_scores)
print(attn_scores.shape)
Out:
tensor([[ 0.0613, -0.3491, 0.1443, -0.0437, -0.1303, 0.1076],
[-0.6004, 3.4707, -1.5023, 0.4991, 1.2903, -1.3374],
[ 0.2432, -1.3934, 0.5869, -0.1851, -0.5191, 0.4730],
[-0.0794, 0.4487, -0.1807, 0.0518, 0.1677, -0.1197],
[-0.1510, 0.8626, -0.3597, 0.1112, 0.3216, -0.2787],
[ 0.4344, -2.5037, 1.0740, -0.3509, -0.9315, 0.9265]],
grad_fn=<MmBackward0>)
torch.Size([6, 6])
이전의 self-attention과 같이, outptut은 6개의 input token들에 해당하는 6x6 tensor를 가집니다.
이전에 scaled dot-product를 softmax function으로 다음과 같이 구했었죠
In:
attn_weights = torch.softmax(attn_scores / d_out_kq**0.5, dim=1)
print(attn_weights)
Out:
tensor([[0.1772, 0.1326, 0.1879, 0.1645, 0.1547, 0.1831],
[0.0386, 0.6870, 0.0204, 0.0840, 0.1470, 0.0229],
[0.1965, 0.0618, 0.2506, 0.1452, 0.1146, 0.2312],
[0.1505, 0.2187, 0.1401, 0.1651, 0.1793, 0.1463],
[0.1347, 0.2758, 0.1162, 0.1621, 0.1881, 0.1231],
[0.1973, 0.0247, 0.3102, 0.1132, 0.0751, 0.2794]],
grad_fn=<SoftmaxBackward0>)
6x6은 self-attention section에서 계산한 attention weights를 의미합니다.
이제 한 단어씩 “예측”하기 때문에 다음과 같은 순서로 GPT는 단어를 내뱉습니다.
- "Life" → "is"
- "Life is" → "short"
- "Life is short" → "eat"
- "Life is short eat" → "desert"
- "Life is short eat desert" → "first"
이것을 가장 단순한게 적용하는 방법은 attention weight에 diagonal하게 mask를 씌우는 것입니다. 이러면 future word 가 context vector를 만드는데에 영향을 줄 수 없습니다.
pytorch의 ‘tril’이라는 function을 이용하면 단순하게 구현할 수 있습니다.
In:
block_size = attn_scores.shape[0]
mask_simple = torch.tril(torch.ones(block_size, block_size))
print(mask_simple)
Out:
tensor([[1., 0., 0., 0., 0., 0.],
[1., 1., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 0., 0.],
[1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1.]])
In:
masked_simple = attn_weights*mask_simple
print(masked_simple)
Out:
tensor([[0.1772, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0386, 0.6870, 0.0000, 0.0000, 0.0000, 0.0000],
[0.1965, 0.0618, 0.2506, 0.0000, 0.0000, 0.0000],
[0.1505, 0.2187, 0.1401, 0.1651, 0.0000, 0.0000],
[0.1347, 0.2758, 0.1162, 0.1621, 0.1881, 0.0000],
[0.1973, 0.0247, 0.3102, 0.1132, 0.0751, 0.2794]],
grad_fn=<MulBackward0>)
이렇게 하면 각 row의 attention weights의 mask된 부분은 서로 합쳐지지 않기 때문에, 영향을 끼칠수 없게됩니다.
In:
row_sums = masked_simple.sum(dim=1, keepdim=True)
masked_simple_norm = masked_simple / row_sums
print(masked_simple_norm)
Out:
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0532, 0.9468, 0.0000, 0.0000, 0.0000, 0.0000],
[0.3862, 0.1214, 0.4924, 0.0000, 0.0000, 0.0000],
[0.2232, 0.3242, 0.2078, 0.2449, 0.0000, 0.0000],
[0.1536, 0.3145, 0.1325, 0.1849, 0.2145, 0.0000],
[0.1973, 0.0247, 0.3102, 0.1132, 0.0751, 0.2794]],
grad_fn=<DivBackward0>)
이제 각 row의 합이 1이 된 것을 볼 수 있습니다.
이를 효율적으로 할 수 있는 방법이 있는데요
기존엔 이런순서지만,

diagonal에 대해 마이너스 무한대를 곱하게 되면 더 효율적으로 mask attention weight를 구할 수 있습니다.

In:
mask = torch.triu(torch.ones(block_size, block_size), diagonal=1)
masked = attn_scores.masked_fill(mask.bool(), -torch.inf)
print(masked)
Out:
tensor([[ 0.0613, -inf, -inf, -inf, -inf, -inf],
[-0.6004, 3.4707, -inf, -inf, -inf, -inf],
[ 0.2432, -1.3934, 0.5869, -inf, -inf, -inf],
[-0.0794, 0.4487, -0.1807, 0.0518, -inf, -inf],
[-0.1510, 0.8626, -0.3597, 0.1112, 0.3216, -inf],
[ 0.4344, -2.5037, 1.0740, -0.3509, -0.9315, 0.9265]],
grad_fn=<MaskedFillBackward0>)
그 다음에 softmax까지 하면, (마이너스 무한대는 softmax에 의해 0이 됨)
In:
attn_weights = torch.softmax(masked / d_out_kq**0.5, dim=1)
print(attn_weights)
Out:
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0532, 0.9468, 0.0000, 0.0000, 0.0000, 0.0000],
[0.3862, 0.1214, 0.4924, 0.0000, 0.0000, 0.0000],
[0.2232, 0.3242, 0.2078, 0.2449, 0.0000, 0.0000],
[0.1536, 0.3145, 0.1325, 0.1849, 0.2145, 0.0000],
[0.1973, 0.0247, 0.3102, 0.1132, 0.0751, 0.2794]],
grad_fn=<SoftmaxBackward0>)
Conclusion
transformer에서 쓰이는 module의 기초에 대해 배워보았는데요, 이것을 구현한 다음에는, 효율적인 process를 위해 optimized implement self-attetntion을 공부해보는 것을 추천합니다. (Flash attention같은 memory footprint와 computational load를 줄여주는 것들)
'DL&ML' 카테고리의 다른 글
| Instruction Pre-Training:Language Models are Supervised Multitask Learners 논문 리뷰 (0) | 2024.09.12 |
|---|---|
| Polyglot-Ko (한국어 LLM) 논문 리뷰 (1) | 2024.01.09 |
| EcomGPT: Ecommerce LLM Instruct tuning paper 리뷰 (1) | 2023.10.11 |
| UniversalNER (0) | 2023.08.29 |
| llama2 간단 요약 (0) | 2023.08.01 |