
728x90
논문 핵심

- 기존 "줄글"만 학습시키던 Pre training 대신, "줄글" + "질문&답변"(instruction)을 학습함으로써, 성능 upgrade
- "줄글"로부터 "질문&답변"(instruction)을 생성하는 LLM(Instruction synthesizer) 학습(Mistral 7B)한 후, inference해서 pre training data 생성
- Domain Specific에서도 좋은 성능을 보여줌
모델 process
1. instruct synthesizer
🚩 instruct synthesizer 학습
- {본문 + QA}형식 instruction task dataset를 사용하여 raw text(줄글)로부터 instruction(질문+답변)을 생성하는 것을 학습
- Mistral-7B로 학습
- Loss는 instruction부분만 학습
- 약 34만 data로 학습 (34개 taks * 각 1만개 사용)
🚩 instruct synthesizer Inference
2. LLM Pre-training
- instruct synthesizer가 만든 instruction을 추가하는것을 제외하고는 Vanilla pre-training과 동일
- 🚩 General instruct pre-training
- 200M중 40M만 뽑아서 instruction synthesizer로 데이터셋 augment
- 20M으로 질문&답변 생성, 두번째 20M으로 concat해서 질문&답변 생성 (총 40M)
- 이를 5번 반복
- 최종적으로 200M instruction pre-training dataset 생성
- 추가로 synthesizer finetuning에 쓰였던 데이터도 pre-training dataset으로 사용
- 20M으로 질문&답변 생성, 두번째 20M으로 concat해서 질문&답변 생성 (총 40M)
- 200M중 40M만 뽑아서 instruction synthesizer로 데이터셋 augment
- 🚩 Domain specific instruct pre-training
- two domains: biomedicine, finance
- 3-round inference 하였음
- 후엔 prompting generalization을 위하여 domain speicific하지않고 general한 instruction도 생성해서 섞었음
3. 성능
🚩 general performance
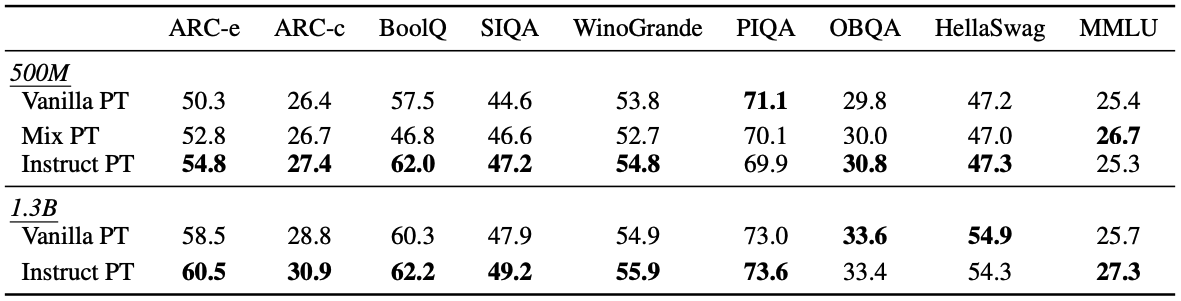
🚩 domain specific performance

🚩 Instruct PT 한것과 안한것의 instruct FT 성능 수렴속도차이

728x90
'DL&ML' 카테고리의 다른 글
| 합성(Synthetic) 데이터 기반 사전학습 (Pre-training) (0) | 2025.07.16 |
|---|---|
| LLM domain adaptation further pre-training에서 최적의 general domain 비율 (0) | 2025.07.16 |
| [Transformer 쉽게 이해하기] - self-attention, multi-haed attention, cross-attention, causal attention 설명과 코드 설명 (0) | 2024.01.19 |
| Polyglot-Ko (한국어 LLM) 논문 리뷰 (1) | 2024.01.09 |
| EcomGPT: Ecommerce LLM Instruct tuning paper 리뷰 (1) | 2023.10.11 |