
728x90
Framework: 일반적인 LLM 학습법임

Pretraining
Ugrade 된 점
- data cleaning
- 1.4T → 2T tokens 사용
- grouped-query attention (GQA) 사용 (병목현상 줄임)
- Context length 2048 → 4096
- 변화 표
Pretraining 학습 그래프: 2T token을 한 번씩 다 학습했는데 아직 수렴이 안되는것을 확인할 수 있다.
Finetuning
Instruction tuning은 양 > 질임
실험결과: 아주 신경써서 만든 Instruction dataset에 training을 할 경우 수 만개의 sample 가지고도 high-quality의 결과가 나왔음. (27,540개의 annotations를 하였음)
details
- epoch수: 2
- lr: 2e-5
- batch size: 64
- sequence length: 4096
RLHF
논문의 주 내용이나, chatbot관련 내용이므로 간단히 요약
- safety, helpfulness 학습했고, GAtt method를 사용하였다.
- 한계점
- multi-turn 대화에서 마지막 generation 부분만 학습에 사용하였음
- 사람이 evaluation해서 주관적이고 noise 존재함
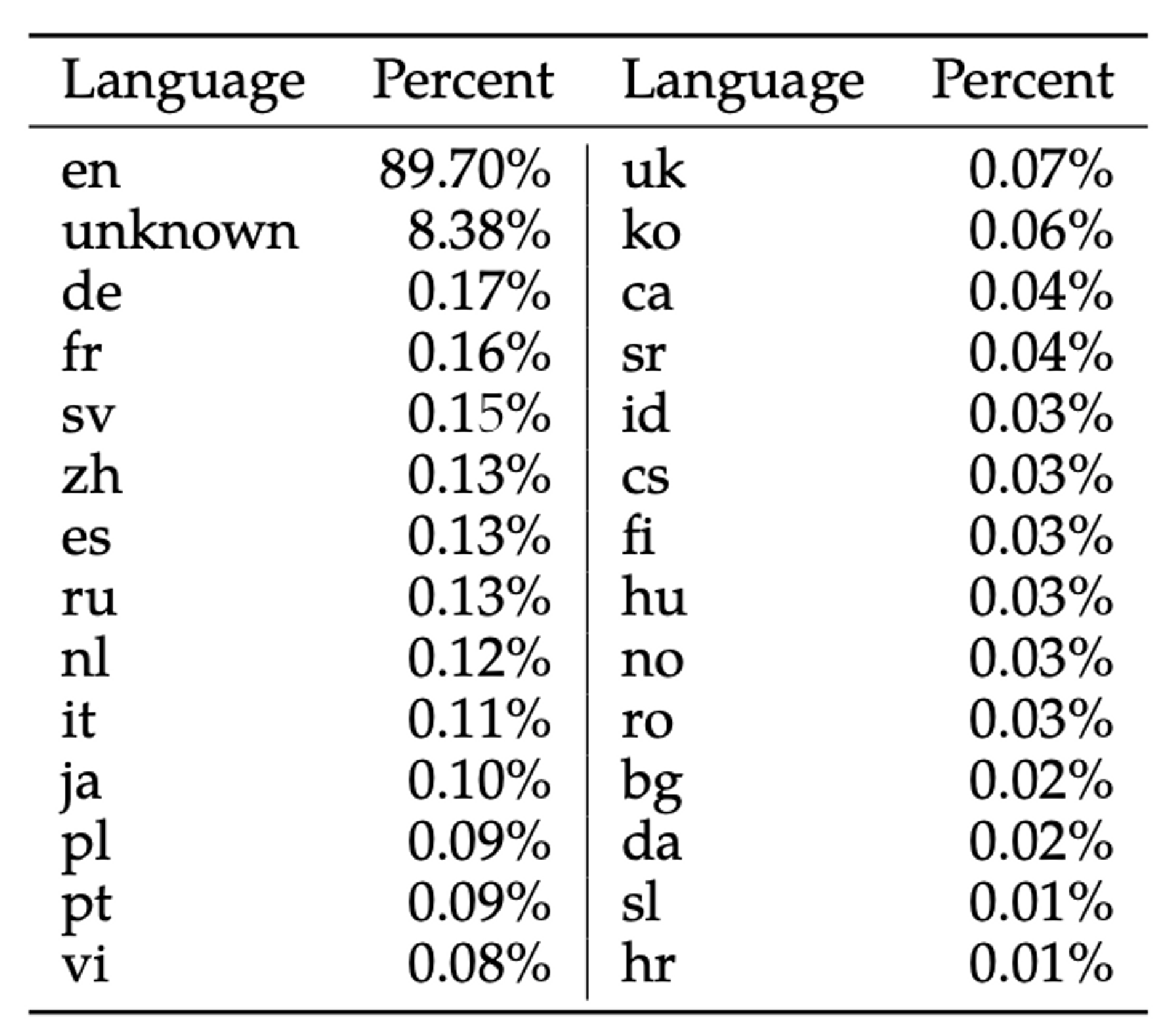
학습셋에서 한국어 비율: 0.06% = 1.2B tokens
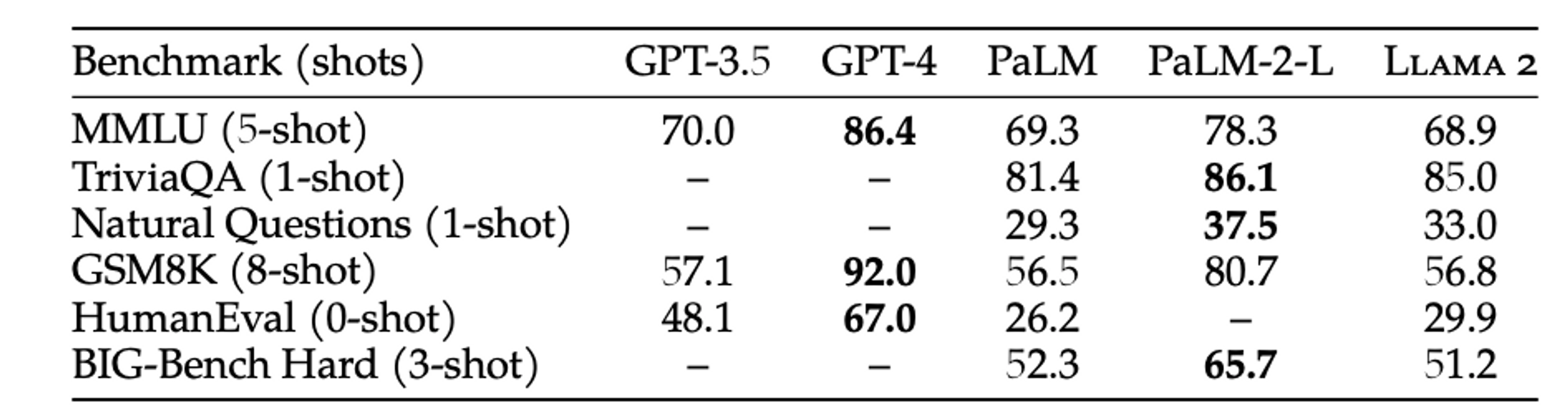
GPT-3.5와 비슷하지만 GPT-4에 비해선 많이 딸림
728x90
'DL&ML' 카테고리의 다른 글
| EcomGPT: Ecommerce LLM Instruct tuning paper 리뷰 (1) | 2023.10.11 |
|---|---|
| UniversalNER (0) | 2023.08.29 |
| LLama1 review (0) | 2023.07.31 |
| GPU란? AI와 가상화폐 (1) | 2023.01.07 |
| db에서 pk_col 이란? (0) | 2023.01.05 |