
728x90
EcomGPT (arxiv, alibaba, 2023.08)
Abstract
- 2.5M 짜리 EcomInstruct에 LLM(BLOOMZ)을 학습시킴
- Ecommerce의 기본 데이터 타입인 상품 정보, 사용자 리뷰등을 이용해서 “atomic task”를 만들어서 data size, diversity를 키움
- Atomic Task: Final task 해결에 의미적 연관성이 있는 task
- Atomic Task ~ Final task의 연관성을 Chain-of-Task라고 함
- 이를 통해 EcomGPT는 훌륭한 zero-shot generalization capability를 가짐
- atomic task로 부터 배운 근본적인 이해 능력이 다른 unseen task를 해결하는데 도움을 줌
Instroduction

E-commerce 데이터가 일반적인 문장들과 다른 점:
- 제품 제목이 일반적으로 별개의 Entity로 구성되어있고 짧음
- 상품정보에서 ## 같은 특수한 기호로 상품속성을 표시하는 경우가 있음
- ex) ProductName##Smartphone
- ex) Brand##Samsung
- unique한 Entity 때문에 general word distribution과 다른 distribution을 가짐
- new product, new users, new trends때문에 새로운 entity들이 계속 생겨남
따라서 cross dataset/task에 강건한 모델이 필요함
- EcomInstruct는 250만, 134 task로 이루어진 dataset
- ?: 이 중 chatgpt pseudo-label개수는 얼마일까
- ?: 원본 몇 -> EcomInstruct 만큼 됐을까
- 두 가지 main source로 이루어짐
- open E-commerce NLP datasets
- NER review based Q&A, product classification, multi-turn dialogue, intent detection
- 장점: Calibrated and High-quality
- Atomic tasks using basic data types of E-commerce dataset (dataset scale-up에 기여)
- basic data types: 상품 정보, 사용자 리뷰, 사용자 발화, search query
- atomic task
- Chain-of-task 예시: NER은 Entity span detection & Entity classification이 필요, review sentiment analysis도 entity span detection이 필요 (이 각각이 atomic task고, 서로 reference함)
- Atomic task 만드는 두 가지 방법
- High quality dataset의 complete information을 rule-base로 transform
- ChatGPT pseudo-labelling
- open E-commerce NLP datasets
Raw Data from Open-Source Benchmarks
- Classification: organize and categorize textual data
- textual data: product descriptions, customer reviews, inquiries.
- predict: category, topic, intent
- classification format: multi-class classification, binary classification, multi-label classification
- Extraction: review-based extractive question-answering: customer review를 이용해서 특정 질문에 답변기능
- Generation: 대화 대답, 카피라이팅, 상품제목(상품 속성에 기반한)
- Others: NER(원본 text에서 추출, 새로운 내용생성하므로 extraction & generation 모두 포함)
Raw Data from Atomic Tasks
- Complete original data의 정보를 이용해서 task를 생성
- Task simplification: simplify original task
- entity detection and entity typing tasks by simplifying NER
- Task Reversal: input, output의 순서를 바꿔서 새로운 task 생성
- QA task를 이용하여 question generation task 생성
- Title generation task를 이용하여 product description task 생성
- Sample Recombination: dataset sample들의 재조합
- 상품매칭 task (카탈로그 매칭)에서 두 상품명과 두 속성이 주어졌을 때, 섞은 다음에 상품 제목과 속성을 매칭하는 task를 만들 수 있음
- Task simplification: simplify original task
- Incomplete original data의 정보를 이용해서 task를 생성: ground truth없이 meta data만 이용
- ChatGPT 이용하여 pseudo-labeling: query rewriting, query segmentation, query-based question generation
Instruction data format (6 components)
- Task description: task가 무엇인지 직접 설명
- Prompt: model의 output에 대해 설명
- Input text
- Candidate label (optional): classification, NER에 필요
- Output Constraints (optional): output format, style
- Output: ground truth

Filtering Instruction data
- rule-based filtering: illegal word, long instance, null instance, white space normalization…
- model-based filtering: Aplpaca GarbageCollector: low-quality intructional data filtering
- secondary check: 각 dataset에 대해 200개 중 하나 random sampling check
EcomGPT
BLOOMZ based model: 560m, 1.7b, 3b, and 7.1b
num_GPU: A100 80GB 4개
batch size: 각 device당 4씩 accumulation해서 8
maximum seq_len: 1024
Experiments
비교 models
BLOOM
BLOOMZ (instruction tuned BLOOM)
CHATGPT (instruction tuned GPT3)
EcomGPT (EcomInstruct tuned BLOOMZ)
Eval metrics
Rouge-L: label과 predict의 correlation을 봄
F1
Dataset
12 tasks (4 major categories: classification, extraction, generation, NER)
- 각 task당 500 instance test
- 나머지 122 dataset은 dataset당 800개씩 sampling해서 train
- 결과적으로 EcomGPT는 85,476개의 E-commerce data에 학습됨
Generalization 측정
다른 모델 실험과 다르게, E-commerce에서 generalization의 중요함을 고려하여, unseen dataset에 test
실험결과에서 눈여겨볼 점
- 560M이 ChatGPT보다 성능이 좋음
- domain에 학습하는 것이 일반화 성능에 영향을 줌
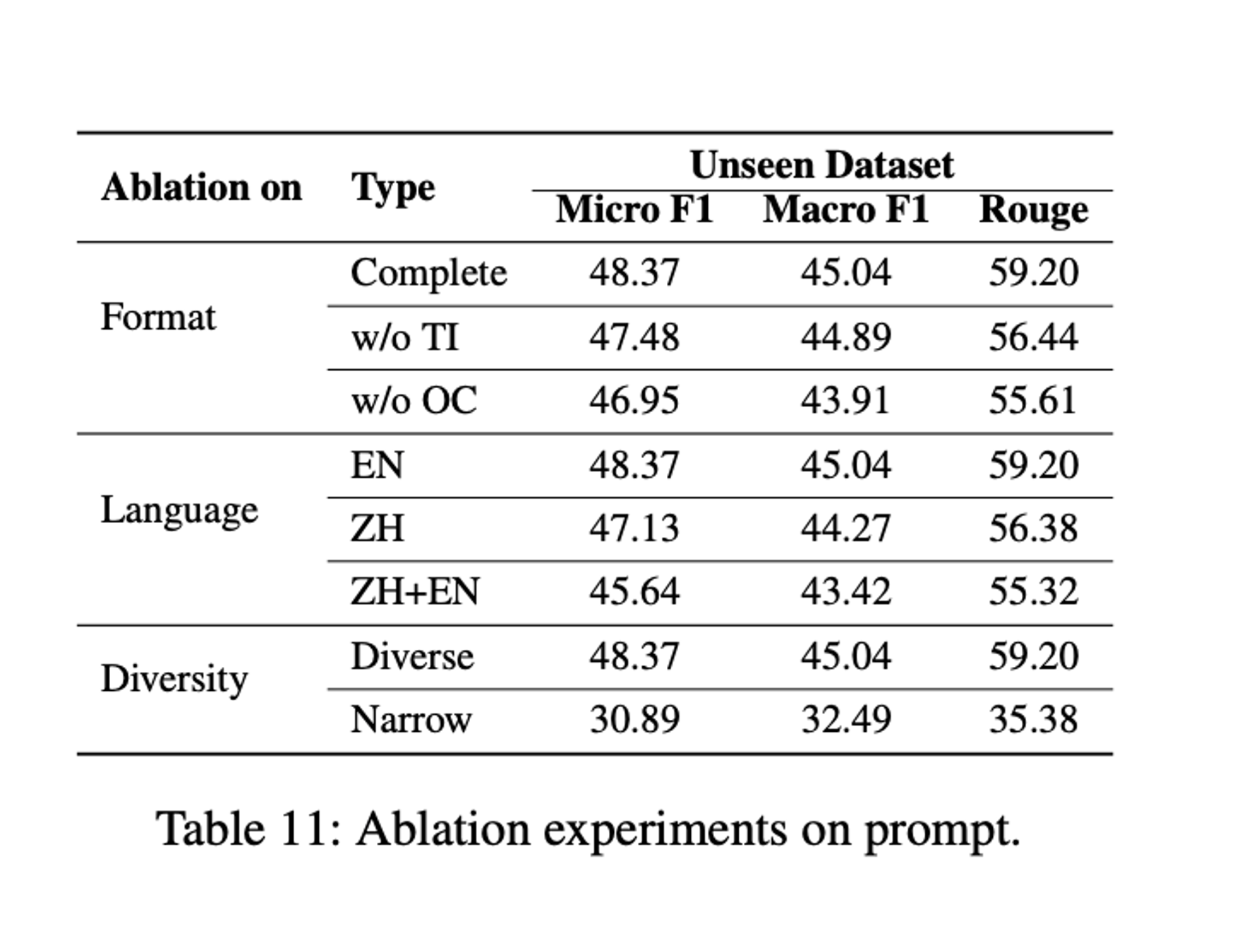
Ablation study
COT task의 이점
일반화 성능 높여줌: 특히 golden label COT가 성능향상에 중요함

- Generalization task에선 QA task가 중요한 역할을 한다.

- dataset 양 늘어날수록 “어느정도까지는” 일반화 성능도 늘어남


- dataset 양 늘어날수록 SFT 성능도 늘어남

- 영어만 학습해도 중국어 성능이 어느정도 나오고, 영어+중국어 학습의 경우 중국어 성능 향상 일어남
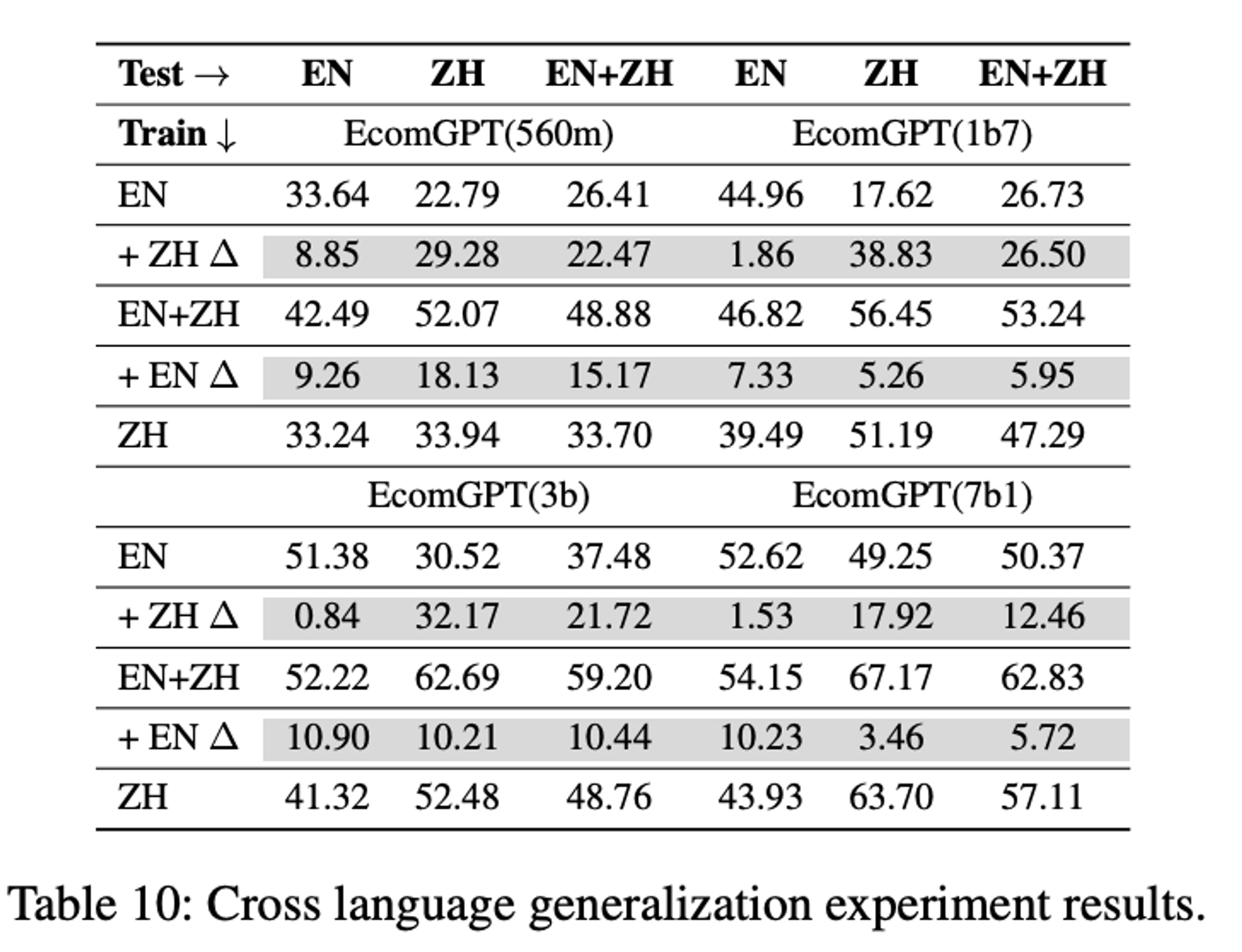
- prompt는 한 나라의 언어로 통일해서 주는것이 좋다
728x90
'DL&ML' 카테고리의 다른 글
| [Transformer 쉽게 이해하기] - self-attention, multi-haed attention, cross-attention, causal attention 설명과 코드 설명 (0) | 2024.01.19 |
|---|---|
| Polyglot-Ko (한국어 LLM) 논문 리뷰 (1) | 2024.01.09 |
| UniversalNER (0) | 2023.08.29 |
| llama2 간단 요약 (0) | 2023.08.01 |
| LLama1 review (0) | 2023.07.31 |