DL&ML
Polyglot-Ko (한국어 LLM) 논문 리뷰
kongsberg
2024. 1. 9. 14:54
728x90
배경: ‘EleutherAI’라는 연구소에서 GPT-NeoX-20B라는 모델을 먼저 만들고, non-english open LLM을 만드려고 하는데, 때, Korean을 먼저 만들어보기로 함. ‘Tunib’ 한국어 데이터를 제공하고 GPT-NeoX기반으로 Polyglot-Ko가 만들어짐. 한국어를 선택하게 된 이유는 창립멤버가 한국인들이 많고, 한국어 데이터 평가셋이 용이했기 때문
모델 크기 종류: 1.3B, 3.8B, 5.8B, 12.8B
Datasets

Preprocessing
- Empty text: text가 없는 Instance들 제거
- Unnecessary spaces: 불필요한 긴 스페이스 제거
- De-identification: 개인 식별 정보 제거
- Uncleaned HTML tags: HTML tag 제거
- Deduplication: exact match일 경우 deduplication
- Short text: 길이가 너무 짧은 data는 제거
- Repeated characters: 반복되는 글자들 제거
- Longer text 일수록 contextual training에 더 좋았음
Model
EleutherAI의 GPT-NeoX codebase를 사용 (256개의 A100s 사용)
Model별 Configuration Setting
1.3B: 213B token 학습, 1024 batch size / 100,000 steps
3.8B: 219B token 학습, 1024 batch size / 100,000 steps
5.8B: 172B token 학습, 256 batch size / 320,000 steps
12.8B: 167B token 학습, 256 batch size(gradient accumulation) / 301,000 steps

Tokenizer : Byte-Level BPE, mecab 형태소분석기 사용
vocab size: 30,003
Evaluation
KOBEST evaluation dataset의 5개 downstream task
- COPA
- HellaSwag
- BoolQ
- SentiNeg
- WiC
실험 결과
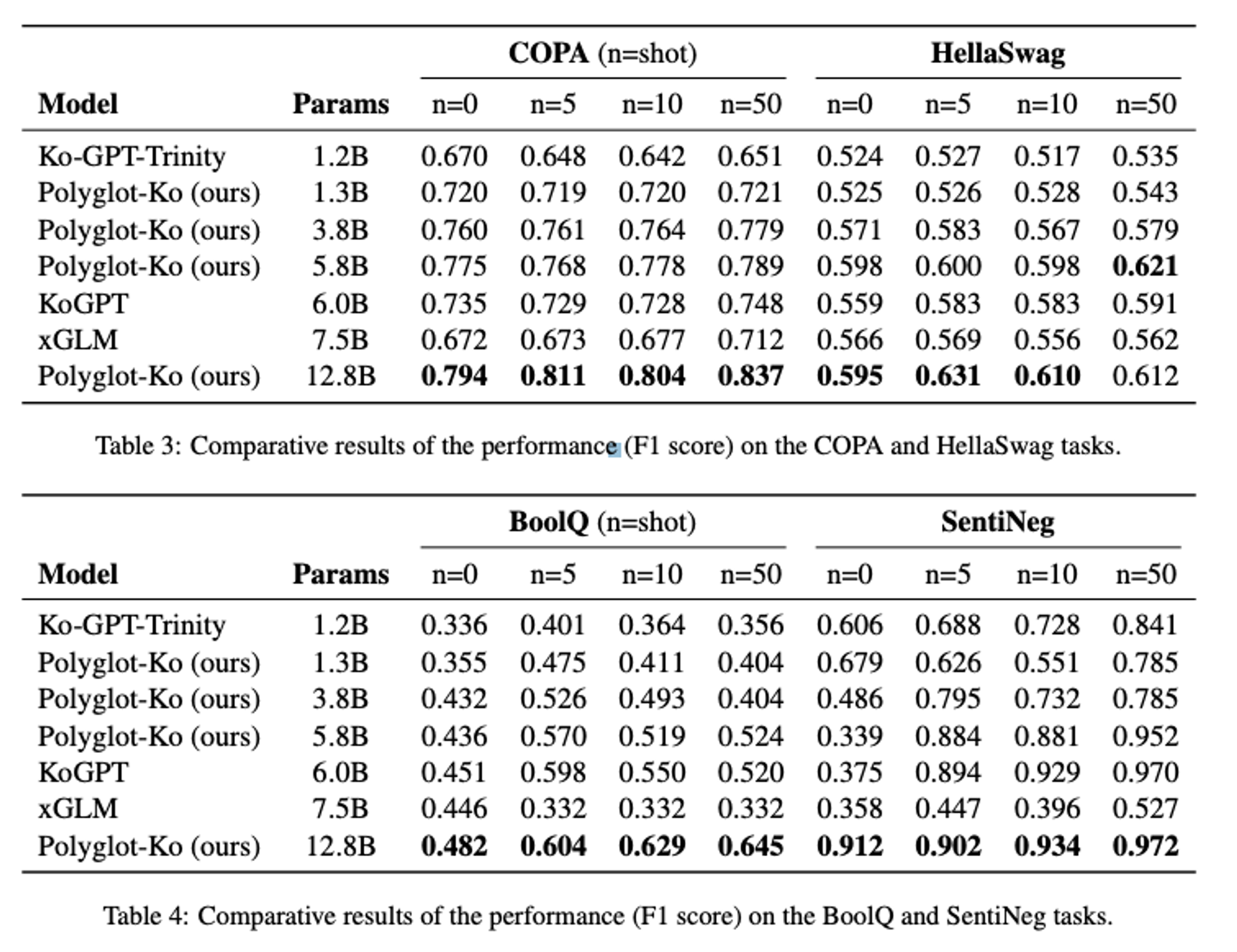
- 추후 Poly-Ko 40B 모델과 Asian(한,중,일 등), Romance 모델을 업데이트할 예정
728x90